1. 延时从库
1.1介绍
是我们认为配置的一种特殊从库.人为配置从库和主库延时N小时.
1.2 为什么要有延时从
数据库故障?
物理损坏
主从复制非常擅长解决物理损坏.
逻辑损坏
普通主从复制没办法解决逻辑损坏
1.3 配置延时从库
SQL线程延时:数据已经写入relaylog中了,SQL线程"慢点"运行
一般企业建议3-6小时,具体看公司运维人员对于故障的反应时间
mysql>stop slave;
mysql>CHANGE MASTER TO MASTER_DELAY = 300;
mysql>start slave;
mysql> show slave status \G
SQL_Delay: 300
SQL_Remaining_Delay: NULL
1.4 延时从库应用
1.4.1 故障恢复思路
(1)监控到数据库逻辑故障
(2)停从库sQL线程,记录已经回放的位置点(截取日志起点)
stop slave sql_thread ;
查看
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 473
(3)截取relaylog
起点:
show slave status \G
Relay_Log_File,Relay_Log_Pos
终点:drop之.前的位置点
show relaylog events in ''
进行截取
(4)模拟sQL线程回访日志
从库 source
(5) 恢复业务
情况一:就一个库的话
从库替代主库工作
情况二:
从库导出故障库,还原到主库中.
1.4.2 故障模拟及恢复
1.主库数据操作
mysql>create database delay charset utf8mb4;
mysql>use delay
mysql>create table t1 (id int);
mysql>insert into t1 values(1);
mysql>drop database relay;
2. 停止从库SQL线程
stop slave sql_thread;
3. 找relaylog的截取起点和终点
起点:
Relay_Log_File: db01-relay-bin.000002
Relay_Log_Pos: 473
终点:
show relaylog events in 'db01-relay-bin.000002'
db01-relay-bin.000002 | 1476 | Query | 7 | 2655 | drop database delay
cd /data/3308/data
mysqlbinlog --start-position=473 --stop-position=1476 /data/3308/data/db01-relay-bin.000002>/tmp/delay.sql
- 从库恢复relaylog
set sql_log_bin=0;
source /tmp/relay.sql
set sql_log_bin=1;
5.从库身份解除
mysql>stop slave;
mysql>reset slave all
2. 半同步 ***
解决主从数据一致性问题
ACK , 从库relay落地, I0线程会返回一个ACK,主库的ACK_reciver.主库事务才能提交.如果一直ACK没收到,超过10秒钟会切换为异步复制.
2.1 半同步复制工作原理的变化
1. 主库执行新的事务,commit时,更新 show master status\G ,触发一个信号给
2. binlog dump 接收到主库的 show master status\G信息,通知从库日志更新了
3. 从库IO线程请求新的二进制日志事件
4. 主库会通过dump线程传送新的日志事件,给从库IO线程
5. 从库IO线程接收到binlog日志,当日志写入到磁盘上的relaylog文件时,给主库ACK_receiver线程
6. ACK_receiver线程触发一个事件,告诉主库commit可以成功了
7. 如果ACK达到了我们预设值的超时时间,半同步复制会切换为原始的异步复制.
2.2 配置半同步复制
加载插件
主:
INSTALL PLUGIN rpl_semi_sync_master SONAME 'semisync_master.so';
从:
INSTALL PLUGIN rpl_semi_sync_slave SONAME 'semisync_slave.so';
查看是否加载成功:
show plugins;
启动:
主:
SET GLOBAL rpl_semi_sync_master_enabled = 1;
从:
SET GLOBAL rpl_semi_sync_slave_enabled = 1;
重启从库上的IO线程
STOP SLAVE IO_THREAD;
START SLAVE IO_THREAD;
查看是否在运行
主:
show status like 'Rpl_semi_sync_master_status';
从:
show status like 'Rpl_semi_sync_slave_status';
3 . 过滤复制
3.1 说明
主库:
show master status;
binlog_do_db 白名单
binlog_ignore_db 黑名单
从库:
show slave status\G
Replicate_Do_DB: 库级别白名单
Replicate_Ignore_DB: 库级别黑名单
Replicate_Do_Table: 表级别白名单
Replicate_Ignore_Table: 表级别黑名单
Replicate_Wild_Do_Table: 表下的模糊白名单
Replicate_Wild_Ignore_Table: 表下的模糊黑名单
3.2 实现过程
从库
[root@db01 ~]# vim /data/3308/my.cnf
replicate_do_db=ppt
replicate_do_db=word
[root@db01 ~]# systemctl restart mysqld3308
主库:
Master [(none)]>create database word;
Query OK, 1 row affected (0.00 sec)
Master [(none)]>create database ppt;
Query OK, 1 row affected (0.00 sec)
Master [(none)]>create database excel;
Query OK, 1 row affected (0.01 sec)
4. GTID复制
4.1 GTID引入
4.2 GTID介绍
GTID(Global Transaction ID)是对于一个已提交事务的唯一编号,并且是一个全局(主从复制)唯一的编号。
它的官方定义如下:
GTID = source_id :transaction_id
7E11FA47-31CA-19E1-9E56-C43AA21293967:29
什么是sever_uuid,和Server-id 区别?
核心特性: 全局唯一,具备幂等性
4.3 GTID核心参数
重要参数:
gtid-mode=on --启用gtid类型,否则就是普通的复制架构
enforce-gtid-consistency=true --强制GTID的一致性
log-slave-updates=1 --强制slave更新是否记入日志
4.4 GTID复制配置过程:
4.4.1 清理环境
pkill mysqld
\rm -rf /data/mysql/data/*
\rm -rf /data/binlog/*
4.4.2 准备配置文件
主库db01:
cat > /etc/my.cnf <<EOF
[mysqld]
basedir=/application/mysql/
datadir=/data/mysql/data
socket=/tmp/mysql.sock
server_id=51
port=3306
secure-file-priv=/tmp
autocommit=0
log_bin=/data/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db01 [\\d]>
EOF
slave1(db02):
cat > /etc/my.cnf <<EOF
[mysqld]
basedir=/application/mysql
datadir=/data/mysql/data
socket=/tmp/mysql.sock
server_id=52
port=3306
secure-file-priv=/tmp
autocommit=0
log_bin=/data/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db02 [\\d]>
EOF
slave2(db03):
cat > /etc/my.cnf <<EOF
[mysqld]
basedir=/applicationmysql
datadir=/data/mysql/data
socket=/tmp/mysql.sock
server_id=53
port=3306
secure-file-priv=/tmp
autocommit=0
log_bin=/data/binlog/mysql-bin
binlog_format=row
gtid-mode=on
enforce-gtid-consistency=true
log-slave-updates=1
[mysql]
prompt=db03 [\\d]>
EOF
4.4.3 初始化数据
mysqld --initialize-insecure --user=mysql --basedir=/application/mysql --datadir=/data/mysql/data
4.4.4 启动数据库
/etc/init.d/mysqld start
4.4.5 构建主从:
master:51
slave:52,53
51:
grant replication slave on *.* to repl@'10.0.0.%' identified by '123';
52\53:
change master to
master_host='10.0.0.51',
master_user='repl',
master_password='123' ,
MASTER_AUTO_POSITION=1; #开启主从复制从1号GTID请求二进制
start slave;
MASTER_AUTO_POSITION=1;读取relaylog最后一个事务的GTID
4.5 GTID 从库误写入操作处理
查看监控信息:
Last_SQL_Error: Error 'Can't create database 'oldboy'; database exists' on query. Default database: 'oldboy'. Query: 'create database oldboy'
Retrieved_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-3
Executed_Gtid_Set: 71bfa52e-4aae-11e9-ab8c-000c293b577e:1-2,
7ca4a2b7-4aae-11e9-859d-000c298720f6:1
注入空事物的方法:
stop slave;
set gtid_next='99279e1e-61b7-11e9-a9fc-000c2928f5dd:3';
begin;commit;
set gtid_next='AUTOMATIC';
这里的xxxxx:N 也就是你的slave sql thread报错的GTID,或者说是你想要跳过的GTID。
最好的解决方案:重新构建主从环境
4.6 GTID 复制和普通复制的区别
非gtid:
CHANGE MASTER TO
MASTER_HOST='10.0.0.51',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_PORT=3307,
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=444,
MASTER_CONNECT_RETRY=10;
gtid:
change master to
master_host='10.0.0.51',
master_user='repl',
master_password='123' ,
MASTER_AUTO_POSITION=1;
start slave;
(0)在主从复制环境中,主库发生过的事务,在全局都是由唯一GTID记录的,更方便Failover
(1)额外功能参数(3个)
(2)change master to 的时候不再需要binlog 文件名和position号,MASTER_AUTO_POSITION=1;
(3)在复制过程中,从库不再依赖master.info文件,而是直接读取最后一个relaylog的 GTID号
(4) mysqldump备份时,默认会将备份中包含的事务操作,以以下方式
SET @@GLOBAL.GTID_PURGED='8c49d7ec-7e78-11e8-9638-000c29ca725d:1';
告诉从库,我的备份中已经有以上事务,你就不用运行了,直接从下一个GTID开始请求binlog就行。
5.MHA高可用
5.1 MHA环境搭建
5.1.1 规划:
1主2从,独立数据库实例
主库: 51 node
从库:
52 node
53 node manager
5.1.2 准备环境(略。1主2从GTID)
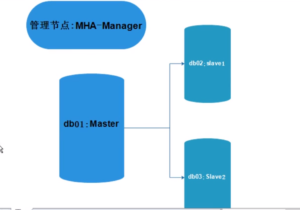
MHA软件构成
Manager工具包主要包括以下几个工具:
masterha_manger 启动MHA
masterha_check_ssh 检查MHA的SSH配置状况
masterha_check_repl 检查MySQL复制状况
masterha_master_monitor 检测master是否宕机
masterha_check_status 检测当前MHA运行状态
masterha_master_switch 控制故障转移(自动或者手动)
masterha_conf_host 添加或删除配置的server信息
Node工具包主要包括以下几个工具:
这些工具通常由MHA Manager的脚本触发,无需人为操作
save_binary_logs 保存和复制master的二进制日志
apply_diff_relay_logs 识别差异的中继日志事件并将其差异的事件应用于其他的
purge_relay_logs 清除中继日志(不会阻塞SQL线程)
5.1.3 配置关键程序软连接
ln -s /application/mysql/bin/mysqlbinlog /usr/bin/mysqlbinlog
ln -s /application/mysql/bin/mysql /usr/bin/mysql
5.1.4 配置各节点免密通信
db01:
rm -rf /root/.ssh
ssh-keygen
cd /root/.ssh
mv id_rsa.pub authorized_keys
scp -r /root/.ssh 10.0.0.52:/root
scp -r /root/.ssh 10.0.0.53:/root
各节点验证
db01:
for i in 51 52 53; do ssh 10.0.0.$i hostname; done
db02:
for i in 51 52 53; do ssh 10.0.0.$i hostname; done
db03:
for i in 51 52 53; do ssh 10.0.0.$i hostname; done
5.1.5 安装软件
下载mha软件
mha官网:https://code.google.com/archive/p/mysql-master-ha/
github下载地址:https://github.com/yoshinorim/mha4mysql-manager/wiki/Downloads
所有节点安装Node软件依赖包
yum install perl-DBD-MySQL -y
rpm -ivh mha4mysql-node-0.56-0.el6.noarch.rpm
在db01主库中创建mha需要的用户
grant all privileges on *.* to mha@'10.0.0.%' identified by 'mha';
Manager软件安装(db03)
yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
rpm -ivh mha4mysql-manager-0.56-0.el6.noarch.rpm
5.1.6 配置文件准备(db03)
创建配置文件目录
mkdir -p /etc/mha
创建日志目录
mkdir -p /var/log/mha/app1
app1:根据自己的业务进行命名
编辑mha配置文件
cat > /etc/mha/app1.cnf <<EOF
[server default]
manager_log=/var/log/mha/app1/manager
manager_workdir=/var/log/mha/app1
master_binlog_dir=/data/binlog
user=mha
password=mha
ping_interval=2
repl_password=123
repl_user=repl
ssh_user=root
[server1]
hostname=10.0.0.51
port=3306
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
EOF
5.1.7 状态检查(db03)
masterha_check_ssh --conf=/etc/mha/app1.cnf
masterha_check_repl --conf=/etc/mha/app1.cnf
5.1.8 开启MHA(db03):
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
5.1.9 查看MHA状态
[root@db03 ~]# masterha_check_status --conf=/etc/mha/app1.cnf
app1 (pid:4719) is running(0:PING_OK), master:10.0.0.51
[root@db03 ~]# mysql -umha -pmha -h 10.0.0.51 -e "show variables like 'server_id'"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 51 |
+---------------+-------+
[root@db03 ~]# mysql -umha -pmha -h 10.0.0.52 -e "show variables like 'server_id'"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 52 |
+---------------+-------+
[root@db03 ~]# mysql -umha -pmha -h 10.0.0.53 -e "show variables like 'server_id'"
mysql: [Warning] Using a password on the command line interface can be insecure.
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| server_id | 53 |
+---------------+-------+
5.2.MHA FailOver 过程详解
5.2.1什么是Failover?
故障转移,
主库宕机一直到业务恢复正常的处理过程(自动)
5.2.2 Failover让你实现怎么做?
(1)快速监控到主库宕机
(2)选择新主
(3)数据补偿
(4)解除从库身份
(5)剩余从库和新主库构建主从关系
(6)应用透明
(7)故障节点处理
(8)故障提醒
5.2.3 MHA的Failover如何实现?
从启动—>故障—>转移—>业务恢复
(1) MHA通过masterha_manger脚本启动MHA的功能.
(2) 在manager启动之前会自动检查ssh互信(masterha_check_ssh)和主从状态(masterha_check_repl)
(3) MHA-manager 通过masterha_master_monitor脚本(每隔ping_interval秒 )
(4) masterha_master_monitor 探测主库3次无心跳之后,就认为主库宕机了.
(5)进行选主过程
算法一:
读取配置文件中是否有强制选主的参数?
candidate_master=1
check_rep1_delay=0
算法二:
自动判断所有从库的日志量.将最接近主库数据的从库作为新主.
算法三:
按照配置文件先后顺序的进行选新主
扩展一下:
candidate_master=1 应用场景
1.MHA+KeepAlive VIP (早期MHA架构)
2.多地多中心
(6) 数据补偿
判断主库SSH的连通性
情况一: SSH能连
调用savebinarylogs脚本,立即保存缺失部分的binlog到各个从节点,恢复
情况二: SSH无法连接
调用apply_ _diff_ relay_ _1ogs 脚本,计算从库的relay1og的差异,恢复到2号从库
(6.1)提供额外的数据补偿的功能@@
(7) 解除从库身份
(8)剩余从库和新主库构建主从关系
(9) 应用透明@@
(10) 故障节点自愈(待开发...)@@
(11) 故障提醒@@
5.2.4MHA应用透明(vip)
master_ip_failover
#!/usr/bin/env perl
use strict;
use warnings FATAL => 'all';
use Getopt::Long;
use MHA::DBHelper;
my (
$command, $ssh_user, $orig_master_host,
$orig_master_ip, $orig_master_port, $new_master_host,
$new_master_ip, $new_master_port, $new_master_user,
$new_master_password
);
my $vip = '10.0.0.55/24';
my $key = "1";
my $ssh_start_vip = "/sbin/ifconfig ens33:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig ens33:$key down";
GetOptions(
'command=s' => \$command,
'ssh_user=s' => \$ssh_user,
'orig_master_host=s' => \$orig_master_host,
'orig_master_ip=s' => \$orig_master_ip,
'orig_master_port=i' => \$orig_master_port,
'new_master_host=s' => \$new_master_host,
'new_master_ip=s' => \$new_master_ip,
'new_master_port=i' => \$new_master_port,
'new_master_user=s' => \$new_master_user,
'new_master_password=s' => \$new_master_password,
);
exit &main();
sub main {
if ( $command eq "stop" || $command eq "stopssh" ) {
# $orig_master_host, $orig_master_ip, $orig_master_port are passed.
# If you manage master ip address at global catalog database,
# invalidate orig_master_ip here.
my $exit_code = 1;
eval {
# updating global catalog, etc
$exit_code = 0;
};
if ($@) {
warn "Got Error: $@\n";
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "start" ) {
# all arguments are passed.
# If you manage master ip address at global catalog database,
# activate new_master_ip here.
# You can also grant write access (create user, set read_only=0, etc) here.
my $exit_code = 10;
eval {
print "Enabling the VIP - $vip on the new master - $new_master_host \n";
&start_vip();
&stop_vip();
$exit_code = 0;
};
if ($@) {
warn $@;
exit $exit_code;
}
exit $exit_code;
}
elsif ( $command eq "status" ) {
print "Checking the Status of the script.. OK \n";
`ssh $ssh_user\@$orig_master_host \" $ssh_start_vip \"`;
exit 0;
}
else {
&usage();
exit 1;
}
}
sub start_vip() {
`ssh $ssh_user\@$new_master_host \" $ssh_start_vip \"`;
}
# A simple system call that disable the VIP on the old_master
sub stop_vip() {
`ssh $ssh_user\@$orig_master_host \" $ssh_stop_vip \"`;
}
sub usage {
print
"Usage: master_ip_failover --command=start|stop|stopssh|status --orig_master_host=host --orig_master_ip=ip --orig_master_port=port --new_master_host=host --new_master_ip=ip --new_master_port=port\n";
}
dos2unix /usr/local/bin/master_ip_failover
chmod +x /usr/local/bin/master_ip_failover
vim /etc/mha/app1.cnf
master_ip_failover_script=/usr/local/bin/master_ip_failover
db01上
手工在主库上绑定vip,注意一定要和配置文件中的ethN一致,我的是eth0:1(1是key指定的值)
ifconfig ens33:1 10.0.0.55/24
重启mha
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
5.1.10 故障模拟及处理
### 停主库db01:
/etc/init.d/mysqld stop
观察manager 日志 tail -f /var/log/mha/app1/manager
末尾必须显示successfully,才算正常切换成功。
修复主库
[root@db01 ~]# /etc/init.d/mysqld start
恢复主从结构
CHANGE MASTER TO
MASTER_HOST='10.0.0.52',
MASTER_PORT=3306,
MASTER_AUTO_POSITION=1,
MASTER_USER='repl',
MASTER_PASSWORD='123';
start slave ;
修改配置文件
[server1]
hostname=10.0.0.51
port=3306
启动MHA
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null> /var/log/mha/app1/manager.log 2>&1 &
5.1.11 Manager额外参数介绍
说明:
主库宕机谁来接管?
1. 所有从节点日志都是一致的,默认会以配置文件的顺序去选择一个新主。
2. 从节点日志不一致,自动选择最接近于主库的从库
3. 如果对于某节点设定了权重(candidate_master=1),权重节点会优先选择。
但是此节点日志量落后主库100M日志的话,也不会被选择。可以配合check_repl_delay=0,关闭日志量的检查,强制选择候选节点。
(1) ping_interval=1
#设置监控主库,发送ping包的时间间隔,尝试三次没有回应的时候自动进行failover
(2) candidate_master=1
#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave
(3)check_repl_delay=0
#默认情况下如果一个slave落后master 100M的relay logs的话,
MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
5.1.12 MHA 的vip功能
参数
master_ip_failover_script=/usr/local/bin/master_ip_failover
注意:/usr/local/bin/master_ip_failover,必须事先准备好
修改脚本内容
vi /usr/local/bin/master_ip_failover
my $vip = '10.0.0.55/24';
my $key = '1';
my $ssh_start_vip = "/sbin/ifconfig eth0:$key $vip";
my $ssh_stop_vip = "/sbin/ifconfig eth0:$key down";
更改manager配置文件:
vi /etc/mha/app1.cnf
添加:
master_ip_failover_script=/usr/local/bin/master_ip_failover
注意:
[root@db03 ~]# dos2unix /usr/local/bin/master_ip_failover
dos2unix: converting file /usr/local/bin/master_ip_failover to Unix format ...
[root@db03 ~]# chmod +x /usr/local/bin/master_ip_failover
主库上,手工生成第一个vip地址
手工在主库上绑定vip,注意一定要和配置文件中的ethN一致,我的是eth0:1(1是key指定的值)
ifconfig eth0:1 10.0.0.55/24
重启mha
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
5.1.13 邮件提醒
1. 参数:
report_script=/usr/local/bin/send
2. 准备邮件脚本
send_report
(1)准备发邮件的脚本(上传 email_2019-最新.zip中的脚本,到/usr/local/bin/中)
(2)将准备好的脚本添加到mha配置文件中,让其调用
3. 修改manager配置文件,调用邮件脚本
vi /etc/mha/app1.cnf
report_script=/usr/local/bin/send
(3)停止MHA
masterha_stop --conf=/etc/mha/app1.cnf
(4)开启MHA
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
(5) 关闭主库,看警告邮件
故障修复:
1. 恢复故障节点
(1)实例宕掉
/etc/init.d/mysqld start
(2)主机损坏,有可能数据也损坏了
备份并恢复故障节点。
2.恢复主从环境
看日志文件:
CHANGE MASTER TO MASTER_HOST='10.0.0.52', MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER='repl', MASTER_PASSWORD='123';
start slave ;
3.恢复manager
3.1 修好的故障节点配置信息,加入到配置文件
[server1]
hostname=10.0.0.51
port=3306
3.2 启动manager
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
5.1.14 binlog server(db03)
参数:
binlogserver配置:
找一台额外的机器,必须要有5.6以上的版本,支持gtid并开启,我们直接用的第二个slave(db03)
vim /etc/mha/app1.cnf
[binlog1]
no_master=1
hostname=10.0.0.53
master_binlog_dir=/data/mysql/binlog
创建必要目录
mkdir -p /data/mysql/binlog
chown -R mysql.mysql /data/*
修改完成后,将主库binlog拉过来(从000001开始拉,之后的binlog会自动按顺序过来)
拉取主库binlog日志
cd /data/mysql/binlog -----》必须进入到自己创建好的目录
mysqlbinlog -R --host=10.0.0.52 --user=mha --password=mha --raw --stop-never mysql-bin.000001 &
注意:
拉取日志的起点,需要主库正在使用的二进制日志点为起点
重启MHA
masterha_stop --conf=/etc/mha/app1.cnf
nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
故障处理
主库宕机,binlogserver 自动停掉,manager 也会自动停止。
处理思路:
1、重新获取新主库的binlog到binlogserver中
2、重新配置文件binlog server信息
3、最后再启动MHA
MHA的故障排查
搭建过程中排查
(1)检查脚本
masterha check_ssh --conf=/etc/mha/app1.cnf
masterha check_repl --conf=/etc/mha/app1.cnf
1主2从复制环境
(2)
配置文件
节点地址,端口
vip和send脚本指定位置和权限
(3) 软连接
切换过程的问题
查看/var/1og/mha/app1/manager
脚本问题比较多一些
vip
send
binlog
恢复MHA故障
(1)检查各个节点是否启动
(2)找到主库是谁?
(3)恢复1主2从
grep "CHANGE MASTER TO" /var/log/mha/app1/manager
(4) 检查配置文件,恢复节点信息
(5) 检查vip和binlogserver
1.检查vip是否在主库,如果不在,手工调整到主库
2.重新启动binlogserver拉取
(6)启动manager
启动: nohup masterha_manager --conf=/etc/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /var/log/mha/app1/manager.log 2>&1 &
检查: masterha_check_status --conf=/etc/mha/app1.cnf
3.管理员在高可用架构维护的职责
1. 搭建:MHA+VIP+SendReport+BinlogServer
2. 监控及故障处理
3. 高可用架构的优化
核心是:尽可能降低主从的延时,让MHA花在数据补偿上的时间尽量减少。
5.7 版本,开启GTID模式,开启从库SQL并发复制。